Authors
Oulis Evangelos |
|
Katsimpras Drosos |
|
Oulis Nikolaos |
|
Kampoli Agathi |
Hadoop
Το Hadoop αποτελεί μία συλλογή από open-source βοηθητικά προγράμματα το αποία προσφέρουν τα απαραίτητα εφόδια για την επίλυση προβλημάτων (υπολογιστικών προβλημάτων) τα οποία διαθέτουν μεγάλο όγκο δεδομένων και υπολογισμών σε ένα πλέγμα υπολογιστών. Η κατάτμηση των δεδομένων και η συνεργασία πολλών υπολογιστικών συστημάτων κάνει αυτό το framework πολύ αποδοτικό ειδικά σε προβλήματα όπου τα δεδομένα είναι σε αυξημένη κλίμακα και οι υπολογσιστικές πράξεις για μία ορισμένη επεξεργασία πολύπλοκες.
Utilities
Το framework αποτελείται από ένα προγραμματισμένο μοντέλο Map Reduce το οποίο αποτελείται από ένα κατανεμημένο σύστημα αποθήκευσης (storage) και βασικές μεθόδους για την επεξεργασία δεδομένων μεγάλης κλίμακας (Big Data Processing) μέσω του προγραμματισμένου μοντέλου.
Why?
Το hadoop έχει αναπτυχθεί για μεγάλα υπολογιστικά συστήματα (clusters) τα οποία αποτελούνται από 2, 3 ακόμα και εκατοντάδες υπολογιστικές μηχανές. Το hadoop εξ' αρχής σχεδιάστηκε έτσι ώστε να συνδυάζει το υλικό τέτοιων υπολογιστικών μηχανών (commodity hardware clusters), το οποίο μπορεί να είναι απλό, με σκοπό την δυμιουργία παράλληλης επεξεργασίας και με μικρό κόστος στην αγορά του υλικού.
How?
Όλα τα κομμάτια του hadoop έχουν αναπτυχθεί με σκοπό την διαχείριση των σφαλμάτων του Hardware με μηχανισμούς που ορίζει το Framework αυτόματα.
Hadoop Description
Ο πυρήνας του hadoop αποτελείται από ένα μέρος που αφορά την αποθήκη των δεδομένων. Αυτή είναι γνωστή ως Hadoop Distributed File System (HDFS), και το μέρος την υπολογιστικής επεξεργασίας δεδομένων και η διαμοίραση της εργασίας σε όλους τους κόμβους της τοπολογίας που είναι γνωστό ως MapReduce programming Model.
Hadoop Destributed File System (HDFS)
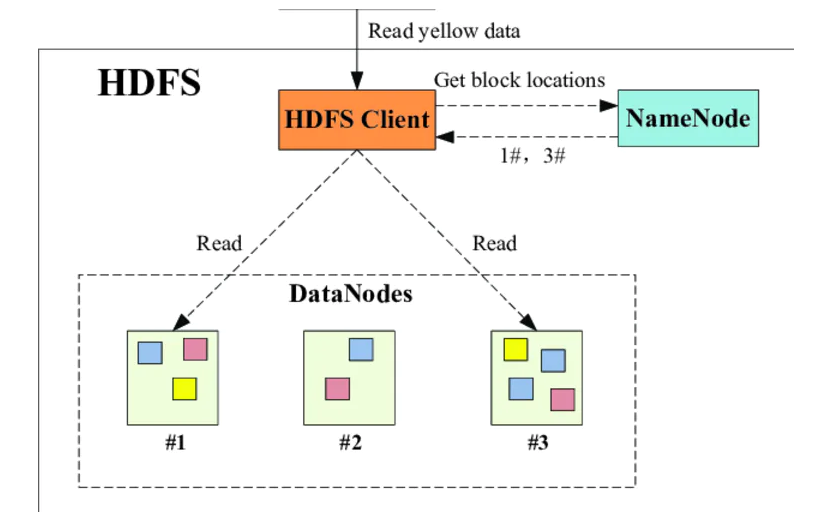
Το HDFS αποτελείται από έναν κατανεμημένο χώρο αποθήκευσης ο οποίος διαμοιράζεται από τις υπολογιστικές μηχανές ενός πλέγματος όπου το Hadoop διαχειρίζεται. Η κύρια λειτουργία του είναι η κατάτμηση των αρχείων σε μεγάλα τμήματα (blocks) και η κατανομή αυτών σε όλες τις μηχανές του πλέγματος (cluster).
Hadoop YARN
Έπειτα ο YARN αναλαμβάνει την διαμοίραση ενός τμήματος του κώδικα ο οποίος είναι χρήσιμος για κάθε μηχανή, όπου τους δίνει τη δυνατότητα εφαρμογής ενός συνόλου εντολών για την παράλληλη επεξεργασία των δεδομένων αντίστοιχα σε κάθε μηχανή. Αυτό δίνει τη δυνατότητα στην κάθε μηχανή του πλέγματος να διαχειρίζεται το δικό της μέρος των δεδομένων σαν να είναι στο τοπικό της σύστημα.
Ο YARN ακόμα αναλαμβάνει την έναρξη της διεργασίας που αφορά την εφαρμογή σε επίπεδο κόμβου.
Hadoop MapReduce
Το προγραμματισμένο μοντέλο MapReduce αναλαμβάνει την συλλογή των αποτελεσμάτων κάθε κόμβου της τοπολογίας και την δημιουργία της εξόδου. Η έξοδος κάθε κόμβου δρομολογείται σε ξεχωριστό αρχείο.
Απόδοση Hadoop
Αυτό επιτυγχάνει μεγάλες ταχύτητες στην επεξεργασία δεδομένων μεγάλης κλίμακας, και ακόμα ταχύτερη μπορεί να γίνει όταν το δίκτυο το οποίο διέπει αυτό το πλέγμα προσφέρει μεγάλες ταχύτητες επικοινωνίες μεταξύ των υπολογιστικών μηχανών.
Hadoop Modules (Συνοπτικά)
-
Hadoop Common – contains libraries and utilities needed by other Hadoop modules,
-
Hadoop Distributed File System (HDFS) – a distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster, oyROEaFv0v
-
Hadoop YARN – (introduced in 2012) a platform responsible for managing computing resources in clusters and using them for scheduling users' applications,
-
Hadoop MapReduce – an implementation of the MapReduce programming model for large-scale data processing.
Εγκατάσταση και Εκτέλεση μίας Clustered Hadoop Υπηρεσίας
Έλεγχος του Cluster μας
Για να πραγματοποιήσουμε έλεγχο του cluster μας θα εκτελέσμουμε την εντολή:
docker node lsέτσι ώστε να πάρουμε σε μία λίστα την κατάσταση και την τοπολογία του cluster-kubernete (leader) καθώς και την κατάσταση κάθε node (slave) του cluster.
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
gcnl3yrd9f8m3eiihdvssw02b * snf-12294 Ready Active Leader 19.03.8
kj7ymjntacu719r3wz10q71wy snf-12296 Ready Active 18.09.7
t7zdlnw882xxv1unel5mt2zij snf-12399 Ready Active 19.03.11
hublulhmmp42s9vhdp3pquyx2 snf-12418 Ready Active 19.03.8Απαραίτητα Πακέτα Που θα Χρειαστούν
Docker
Το Docker είναι ένα σύνολο Platform-as-a-Service (PaaS) προϊόντων που χρησιμοποιεί εικονικοποίηση σε επίπεδο λειτουργικού συστήματος (OS-level virtualization) για την μεταφορά λογισμικού σε πακέτα τα οποία καλούνται Containers. Τα Containers είναι απομονομένα το ένα από το άλλο και φέρουν το καθένα τα δικά του λογισμικά, βιβλιοθήκες και αρχεία παραμετροποίησης (configuration files).
Τα Containers μπορούν να επικοινωνήσουν μεταξύ διαμέσου καλά ορισμένων καναλιών. Όλα τα Containers τρέχουν από ένα μόνο πυρήνα λειτουργικού συστήματος (Operating System kernel) και ως εκ' τούτου χρήζουν λιγότερες απαιτήσεις στους πόρους ενός υπολογιστικού συστήματος σε σχέση με τα Virtual Machines.
Το λογισμικό που φυλοξενεί (hosts) πολλά Containers καλείται Docker Engine.
Docker Compose
Το Docker Compose είναι ένα εργαλείο το οποίο ορίζει/παραμετροποιεί και τρέχει ένα multi-container Docker application. Για την χρήση αυτού του εργαλείου είναι υποχρεωτική η χρήση αρχείου YAML για την παραμετροποίηση μιας υπηρεσίας μιας εφαρμογής. Έπειτα, με μία απλή εντολή μπορεί κανείς να δημιουργήσει και να εκκινήσει όλες της υπηρεσίες που έχουν περιγραφεί σε αυτό το YAML αρχείο.
GitHub
Ακόμα θα πρέπει να έχουμε πρόσβαση στο GitHub. Αυτό προειποθέτει να έχουμε ένα Git client.
Setting Up a Hadoop Cluster Using Docker
Για την εγκατάσταση του Hadoop σε ένα Docker, πρώτα απ' όλα χρειαζόμαστε μία εικόνα του Hadoop (Hadoop Docker Image). Για την παραγωγή της εικόνας (Image), θα χρησιμοποιήσουμε έναν έτοιμο πρότζεκτ το οποίο δίνεται από την βιβλιογραφεία ως Big Data Europe και είναι ανοιχτό στο GitHub.
git clone git@github.com:big-data-europe/docker-hadoop.gitΠαραγωγή των Docker Image
Για την παραγωγή όλων των Docker Images θα χρησιμοποιήσουμε το αρχείο Makefile που διαθέτει το project. Με την εντολή (make) γίνεται η παραγωγή των απαραίτητων Docker Images. Έπειτα τα dockers που δημιουργήθηκαν μπορούμε να τα ερευνήσουμε εκτελώντας την εντολή docker images . Ένα στιγμιότυπο της μηχανής leader παρουσιάζεται παρακάτω.
REPOSITORY TAG IMAGE ID CREATED SIZE
bde2020/hadoop-resourcemanager 1.1.0-hadoop2.7.1-java8 c1e9b215cb9b 9 hours ago 1.37GB
bde2020/hadoop-historyserver 1.1.0-hadoop2.7.1-java8 495fd0b43074 9 hours ago 1.37GB
bde2020/hadoop-nodemanager 1.1.0-hadoop2.7.1-java8 d61cf73e6c0c 9 hours ago 1.37GB
bde2020/hadoop-datanode 1.1.0-hadoop2.7.1-java8 51340609864b 9 hours ago 1.37GB
bde2020/hadoop-namenode 1.1.0-hadoop2.7.1-java8 69b2a3c5f4dd 9 hours ago 1.37GB
bde2020/hadoop-submit master e9f7299c31a5 9 hours ago 1.37GBDocker Compose Services
Έπειτα μέσω ενός YAML αρχείου θα κάνουμε expose τις απαραίτητες υπηρεσίες σε κάθε κόμβο της τοπολογίας του ενός leader και των τεσσάρων slaves. Η τοπολογία που χρησιμοποιήσαμε στο cluster που διαθέτουμε είναι η εξής:
-
expose τεσσάρων κόμβων ως κόμβους οι οποίοι θα προσφέρουν του υπολογιστικούς πόρους τους για την επεξεργασία δεδομένων.
-
expose ενός κόμβου ως manager, HDFS και YARN.
Παρακάτω θα απαριθμήσουμε την κάθε υπηρεσία όπου το docker compose κάνει expose.
-
nodename : Υπηρεσία η οποία γίνεται expose σε έναν κόμβο της τοπολογίας, στον leader κόμβο του cluster μας. Το NodeName αποτελεί κομβική υπηρεσία του HDFS. Πρακτικά είναι υπεύθυνος να κρατάει το direcotry tree όλων των αρχείων του System File, και καταγράφει την θέση κάθε δεδομένου (data) κατά μήκος του Cluster.
-
datanode : Υπηρεσία η οποία γίνεται expose σε όλους τους κόμβους της τοπολογίας ως κόμβοι οι οποίοι θα μπορούν να εκτελέσουν υπολογισμούς. Τα DataNode στιγμιότυπα έχουν την ικανότητα να επικοινωνούν μεταξύ τους, το οποίο γίνεται όταν οι DataNodes αναπαράγουν τα data.
-
resource manager: Υπηρεσία η οποία γίνεται expose μόνο στον leader κόμβο της τοπολογίας μας. Ουσιαστικά αυτή η υπηρεσία αφορά τον YARN ο οποίος είναι υπεύθυνος για την διαχείριση των υπολογιστικών πόρων και των πόρων του δικτύου που διέπει τις μηχανές, την χρονοδρομολόγηση των Tasks και τον προγραμματισμό της εφαρμογής (e.g. MapReduce jobs).
-
node manager: Υπηρεσία που γίνεται expose σε όλους τους κόμβους της τοπολογίας. Αποτελεί μία ειδική περίπτωση TaskTracker ο οποίος είναι πιο ευέλικτος από τον TaskTracker. Είνα υπεύθυνος για τον δυναμική δέσμαυση των πόρων κάθε μηχανής. Ακόμα, για τον Node Manager ισχύει ότι αποτελεί ένα deamon του YARN.
-
history server: Υπηρεσία που τρέχει μόνο στον leader του cluster μας. Εκτελεί ένα REST-API το οποίο επιτρέπει στον τελικό χρήστη να αποκτήσει την κατάσταση κάθε εφαρμογής MapReduce η οποία έχει τερματίσει.