1. Project description
2. Tools / services
3. The project
3.1. First part : Deploying the network
3.2. Second part: Storing data in a database
Although, storing data in files is enought for testing the tool, for the needs of our, total, project we connected the swarm with a mongoDB replica. The databases was uploaded in the lab network via the swarmlab service and it works as the following image indicates.
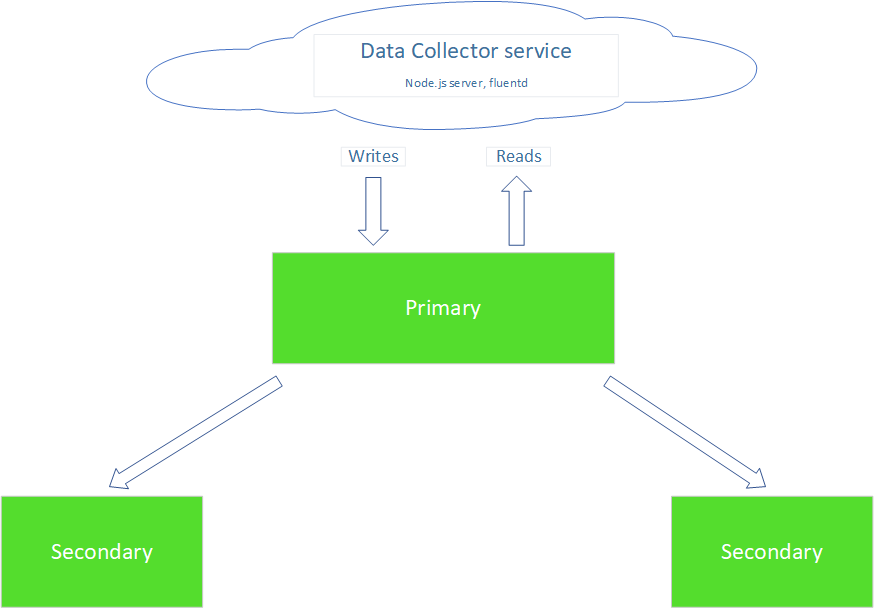
In the mongoDB replica network, we find 3 machines running a mongoDB service. The Primary is the first tasked with storing data, incomming from the Data Collector service, and presenting them back. If Primary is not available, one of the other two will carry through the jobs needed.
From the Primary, or any other machine, of the mongoDB replica network, follo the steps:
| 1 | mongo After connecting with the machine, run this command to enter the database’s interface. |
| 2 | use app_swarmlab Use this database, where data from the swarm will be stored in a collection. |
| 3 | db.auth('app_swarmlab','app_swarmlab') Connect as admin to the database. |
| 4 | db.logs.find({}).sort({_id:-1}) View logs in a descending order. |